fisher-yates shuffle
Fisher-Yates Shuffle Algorithm Explained: Why It's the Key to Fair Random Groups
Learn how the Fisher-Yates shuffle algorithm works, why it produces unbiased random permutations, and how it ensures fairness in random group generators, pair generators, and student pickers. Step-by-step explanation with real examples.
Fisher-Yates Shuffle Algorithm Explained
Have you ever used an online random group generator and wondered how it shuffles names so that every student has an equal chance of being in any group? The secret is a deceptively simple algorithm known as the Fisher-Yates shuffle (also called the Knuth shuffle). This algorithm is the gold standard for producing unbiased random permutations—exactly what’s needed when you split a list into groups, pick partners, or select a student at random. In this article, we’ll break down exactly how it works, why it’s fair, and how tools like the Random Group Generator rely on it to give you trustworthy results every time.
The Problem of Bias in Randomization
When you need to mix up a list—whether it’s student names, team members, or presentation topics—the goal is equal opportunity. A truly random shuffle should give every possible order the same chance of appearing. But not all shuffling methods achieve that. Many quick-and-dirty approaches introduce subtle (and sometimes not-so-subtle) biases that can favor certain arrangements over others.
Consider a naive method: loop through the array and swap each element with a randomly chosen element from anywhere in the array. At first glance it seems fair, but mathematically it allows n^n possible sequences of random choices, while there are only n! possible permutations. Since n^n is not a multiple of n! for n > 2, some permutations end up more likely than others. In a classroom where you rely on random grouping to break up cliques or ensure mixed-ability teams, that bias can subtly undermine your intent.
Another common shortcut is using a sorting function with a random comparator—like array.sort(() => Math.random() - 0.5). While this might look random, it doesn’t guarantee that each comparator call is consistent, and the resulting distribution is often not uniform. In practice, some elements tend to stay near their original positions more than they should. For an educator who shuffles a roster month after month, such patterns can become noticeable and erode trust in the tool.
For fair grouping, you need an algorithm that mathematically guarantees each permutation is equally likely. That’s where the Fisher-Yates shuffle comes in.
How the Fisher-Yates Shuffle Works (Step-by-Step)
The Fisher-Yates shuffle was first described by Ronald Fisher and Frank Yates in 1938, but the version we use today was popularized by Donald Knuth in The Art of Computer Programming. It’s elegant, efficient, and provably unbiased.
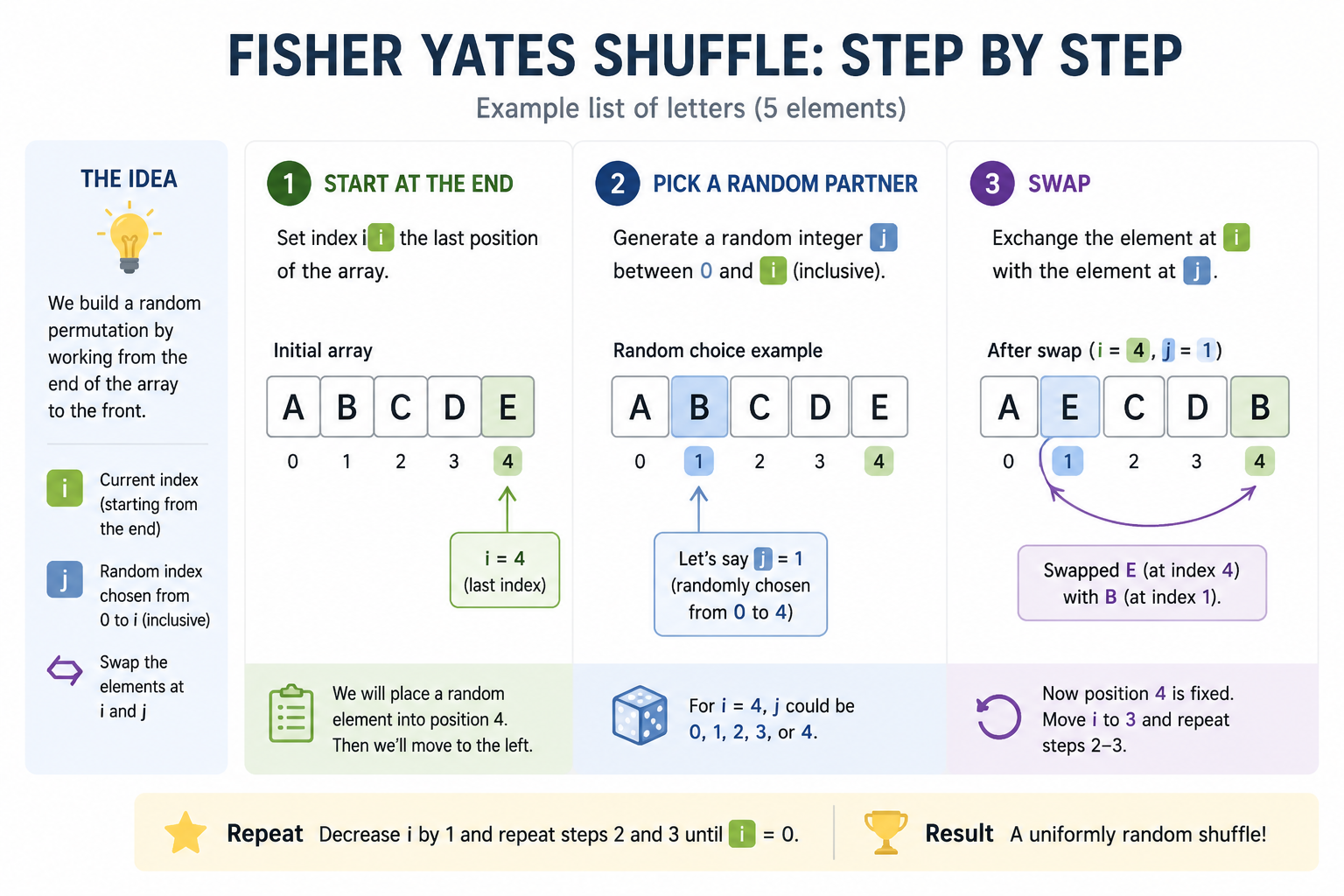
The modern algorithm operates in-place and runs in O(n) time. Here’s how it works, using an example list of letters: [A, B, C, D, E].
- Start at the end. Set an index
ito the last position of the array (index 4 for our 5-element list). - Pick a random partner. Generate a random integer
jbetween 0 andiinclusive. This is the position you’ll swap with. Fori=4,jcould be 0, 1, 2, 3, or 4. - Swap. Exchange the element at
iwith the element atj. In our example, ifj=1, swapE(at index 4) withB(at index 1). The array becomes[A, E, C, D, B]. The last element is now fixed in its final permuted position. - Move left. Decrease
iby 1 (moving to index 3) and repeat from step 2. This time, only positions 0 through 3 are eligible for the random choice. The element that ends up at index 3 is now permanently placed. - Repeat until
ireaches 1. Once you’ve processed all positions down to index 1, the entire array is shuffled. There’s no need to process index 0 alone—it will already be the only element left.
Here’s a visual walkthrough of a complete shuffle:
Start: [A, B, C, D, E]
i=4, j=1 -> swap E and B → [A, E, C, D, B]
i=3, j=3 -> swap D and D → [A, E, C, D, B] (no change)
i=2, j=0 -> swap C and A → [C, E, A, D, B]
i=1, j=1 -> swap E and E → [C, E, A, D, B] (no change)
Result: [C, E, A, D, B]Notice that each step permanently places one more element at the right end of the array, narrowing the pool of items that can still be moved. Because the random index always includes the current position itself, an element can end up staying where it is—that’s part of what makes the distribution uniform.
Why Fisher-Yates Is the Gold Standard for Fair Shuffling
The beauty of Fisher-Yates lies in its mathematical guarantee of uniform randomness. At any step i, every element still under consideration (positions 0 through i) has exactly a 1/(i+1) chance of being chosen to land at position i. Multiply these independent probabilities across the whole array, and the result is that every possible permutation of the original list has a 1/n! probability of being generated—exactly what we mean by a fair shuffle.
This contrasts sharply with alternative approaches. The “swap with any index” method mentioned earlier distorts the probability because the same element can be moved multiple times in unpredictable ways, creating a non-uniform outcome. Sorting with a random comparator not only lacks the uniformity proof but also suffers from performance inconsistencies: it relies on the sorting algorithm’s behavior, which was never designed for random ordering and can make more comparisons than necessary.
Beyond fairness, Fisher-Yates is practical. It runs in linear time, requires no extra memory beyond a single swap variable, and is straightforward to implement correctly in any programming language. For web-based tools that shuffle lists in real time—like a random pair generator or student picker—the algorithm’s speed means instant results, even for large rosters of hundreds or thousands of names.
Real-World Applications: Grouping, Pairs, and Student Picking
On random-group-generator.com, the Fisher-Yates shuffle is the engine behind every shuffle you see. Whether you’re using the Random Group Generator, the Random Pair Generator, or the Random Student Picker, the tool starts by taking your list of names and applying Fisher-Yates to put them in a completely random order.
Once the list is shuffled, the rest is simple:
- Group generation: The shuffled list is sliced into chunks of the desired group size. For example, a teacher with 30 students who wants 6 groups of 5 simply enters the names and sets the group size to 5. The algorithm shuffles the list, and the first 5 names become Group 1, the next 5 Group 2, and so on. Because the order is uniformly random, every possible set of 5 names has an equal chance of ending up together.
- Pair generation: The tool splits the shuffled list into pairs. If the number is odd, the last pair might be a trio or a leftover, depending on your settings.
- Student picking: For a quick random pick, the tool simply grabs the first name from the shuffled list. This is exactly equivalent to drawing a name from a hat—fair and unpredictable.
Consider a workshop facilitator who needs to form breakout groups of mixed departments on the fly. They paste the participant list into the group generator, hit shuffle, and instantly get groups. Behind the scenes, Fisher-Yates ensures that no department ends up over-represented by chance any more than it would in a perfectly random draw. This transparency builds trust: facilitators can confidently tell participants that the computer isn’t playing favorites.
Even the Group Name Generator can benefit from Fisher-Yates when it randomizes word combinations to create unique, fun group names—like “Creative Clouds” or “Brilliant Bison.” The algorithm shuffles words from predefined lists, making every name suggestion fresh and unpredictable.
FAQ
Does the Fisher-Yates shuffle guarantee 100% fairness?
Yes—mathematically, it ensures that every possible permutation of a list is equally likely, provided that the random number generator used to pick the indices is itself uniform. In practice, modern computers use pseudorandom number generators that are indistinguishable from true randomness for grouping tasks, so the fairness is excellent.
How is the Fisher-Yates shuffle different from using array.sort() with Math.random()?
Sorting with a random comparator is neither efficient nor guaranteed to be uniformly random. It relies on the sorting algorithm’s internal logic, which may not treat all comparisons equally, leading to a biased distribution. Fisher-Yates is designed specifically for shuffling and provably yields each permutation with exact probability 1/n!.
Can the algorithm handle large lists without slowing down?
Absolutely. Because Fisher-Yates runs in linear time (O(n)), its execution time grows in direct proportion to the list size. Shuffling 1,000 names takes just a fraction of a second in a browser, and even 10,000 names feels instant on modern devices.
How does the Random Group Generator website implement the Fisher-Yates shuffle?
The site runs the algorithm directly in your browser using JavaScript. When you click “Generate,” your list is passed through a Fisher-Yates shuffle that uses the browser’s Math.random() function to select random indices. The shuffled list is then split into groups or pairs. Your data never leaves your device, and the same algorithm runs identically every time.
Is it still random if the random number generator isn’t truly random?
For grouping and selection purposes, pseudorandom generators like Math.random() are more than sufficient. They produce sequences that pass statistical tests for randomness and are unpredictable in practical terms. Unless you’re running a cryptographic lottery, you won’t notice any difference from “true” randomness.
Ready to create unbiased random groups? Try our Random Group Generator now—it’s free, fast, and powered by the Fisher-Yates shuffle for true fairness.